Big data Odoo optimization is a very important issue because when Odoo is used by big companies, it implies that the system is used extensively and that goes hand in hand with very fast and sustained data growth. Obviously, the most impacted standard tables will be the ones we call the “_lines” tables such as:
sales_order_line
account_move_line
stock_move_line
The issue
To evaluate the impact of generic data growth on these tables, let’s imagine a standard company with 10 branches and 2 accounting persons validating 100 invoices each per open day. Let’s be fair and set the average number of sales_invoice_line per invoice at 10 items per invoice. The results would be the following:
100 invoices X 10 items per invoice = 1,000 invoice lines.
1,000 invoice lines will generate 1,000 product lines + 100 tax lines + 100 total invoice amount lines inside the Sales Journal if we configured the latter to write account_moves PER PRODUCT, which is the only good way of pulling later good Dashboarding values per account or per product category etc… Anyways, this means 1,200 account_move_lines per user per day.
Multiplied by 2 users, this gives us 2,400 account_move_line entries per branch per day.
Multiplied by 10 branches, this gives us 24,000 account_move_line entries per company per day.
Multiplied by 25 open days, we get 24 000 X 25 = 600,000 account_move_lines per month.
Yearly, we get 600,000 x 12 = 7,200,000.
Beyond 3 million lines, you will start feeling an important impact on performance.
Beyond 5 to 6 million lines, you will be heavily penalized. Of course, this depends on your hardware, disk technology, CPU availability, queuing strategy….. but all in all, in our present case, there is more bad news coming:
7,200,000 account_move_line entries stand for purely validated invoices….. but this means that the sales_order_lines table can be 2 to 10 times bigger within the same period because it also contains quotations. Let’s be fair and assess that you convert 30% of your quotations into sales: your sales_order_line table will be about 3 times bigger: that’s a rough 21,000,000 entries per year we are talking about.
You have just as much coming into stock move lines tables.
I’m not even talking about MRP which can make even bigger tables along with lot numbers etc… if this client is doing production as well.
I’m assuming this is a MONO COMPANY system …. otherwise, you will end up with data from different companies inside the same tables… Picture this multiplied by 3 companies inside the same tables!
I’m assuming you have a dedicated server and dedicated resources per company, but it is not always the case since many people mutualize hosting.
Now, if we consider you have around 30 users accessing these basic and most important tables simultaneously and a couple of them are trying to do Dashboarding while the rest try to work…well… Forget it! Go buy yourself some coffee or subscribe to Zen classes.
Measuring the performance gap
Many of our clients including IT departments, other Odoo Partners and Independent developers have asked us to optimize their implementations because the system was slowing down. I spent some time playing with the following in order to give you a true insight on Big data Ddoo optimization. My test kit consisted of the following:
1 XEON E5 – 6 cores CPU 2Ghz
8 Gigs of RAM
SSD Hard Drive 256 Gb
Ubuntu 16.04
PostgreSQL 9.5
Test done with and without PgBouncer
Fake data generated for the occasion inside the account_move/ account_move_line tables
Here are the results of my measuring the following:
Selecting all Journal Items from All journals
Grouped by period
Effective date greater than…
Effective date lesser than…
With total SUM calculated for Credit / Debit columns at the bottom
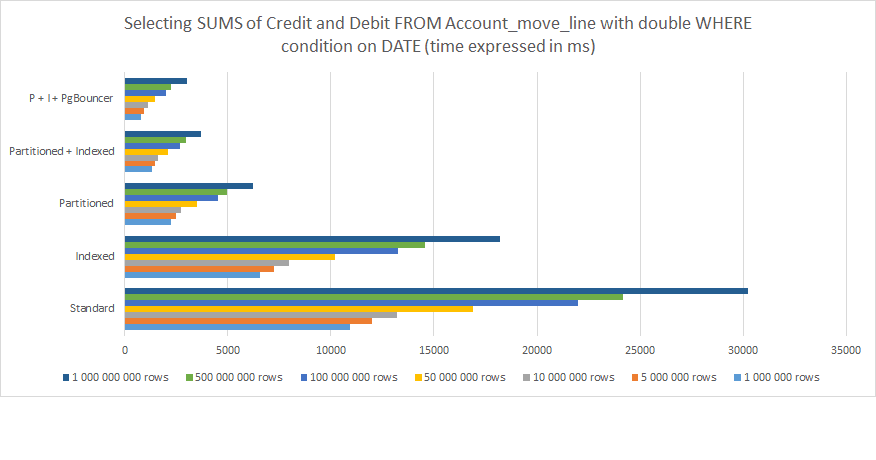
From the above, one can clearly understand that:
Indexing helps but is not enough in the long run
Partitioning works a lot better
Combining Partitioning and Indexing works even better
Combining Partitioning and Indexing and associating them with PgBouncer gives the best results.
For 1,000,000,000 rows, the performance difference between a standard out-of-the-box PostgreSQL Odoo structure and Optimized with Partitioning, indexing and PgBouncer drops from 30,000 ms (30 seconds) to less than 3,000 ms (3 seconds). Yet, keep in mind this is only one request from one single user. Put this in perspective with 30 or more concurrent users and you understand this is the difference between a system that runs and one that just systematically times out and causes error until it ultimately crashes.
If you are skeptical about the data collected above for Big Data Odoo optimization, please, take a look at this post: PostgreSQL: Partitioned Table vs Non-Partitioned Table. This is not dedicated to Odoo and deals with simpler tables inside PostgreSQL but the approach is very straightforward and accurate… and conclusions are quite identical.

Are you looking to optimize a large volume of data in your system?
Implementing Your Large Data Odoo Optimization Strategy
If you are reading this post, it means that you either consider providing big data solutions with Odoo or PostgreSQL as a base or that you are already experiencing slowness. Yet, be aware that slowness can come from different reasons:
You left your PostgreSQL configured by default setup. There is a lot to do on that side in order to exploit the true potential of your PostgreSQL server/cluster and default settings must definitely be replaced with a proper resource and usage strategy.
You have a session queuing and HBA auth issue or both: learn to use PgBouncer.
If your case if none of these two applies, then you probably need to step into Indexing and Partitioning indeed and my recommendations are the following:
Beware that indexing can become expensive in resources, especially if you play with string values.
Putting Indexing everywhere is a WRONG approach. Only put it where you know the ORM and your modules are prone to push and pull values from.
Define a partitioning strategy from the start and don’t wait until your tables get huge. You KNOW your client’s profile, turnover, users and this MUST be anticipated.
Your partitioning strategy must follow data growth orientations. Every client is different. This is always a “per case” process.
Apply partitioning table-structure logic that follows the triggers’ logic.
Beware of wrong-defined trigger rules that can cause data-overlap or infinite loops.
Partitioning Rules work… but from experience, Triggers just work BETTER with Odoo. So, just stick to triggers
If your PostgreSQL version is 11 or above, then I highly recommend that you resort to partition inheritance.
Be gentle with Triggers. If you need complexity, put it into the function instead.
Stretch your child-partitions according to the Odoo or Data pattern.
Use Constraint Exclusions to optimize your query speed. To be able to do so, remember to structure your partitioning according to these exclusions.
If you already have a slow system and need to resegment your data through a Big data Odoo optimization partitioning process, you should follow the below guidelines:
Apply the above recommendations too.
Remember Odoo does not know you are modifying the data structure inside PostgreSQL. Doing it the right way implies that you preserve all parent-table names, columns, data format and inter-table constraints.
Checksum your data before and after resegmentation/partitioning. YES, it is basic… but you need to be sure everything is there.
Remember to aim for the future as well. Splitting data per year for past data but not splitting it for the years to come is a BIG mistake. Remember PostgreSQL will go as slow as the slowest requests of all. So, if you consider splitting nicely the past 5 heavy completed years and then leave a big mess as an active table for all the rest that keeps growing, you solved absolutely nothing… and only make things messy. The performance will be degraded just as much.
Port Cities - global team with expertise in Odoo Big Data Optimization
If you feel like Big Data optimization is a too specialized subject for your internal team as one single mistake may compromise data integrity, you should consider having this integrated by a team that has experience in both Odoo and PostgreSQL. Port Cities has a global team of over 80 in-house developers ready to assist you with your Big Data optimization.
Contact us for more information on how to optimize your data and improve your system performance as your company grows.
